GDGoC 1주차 고급자바 스터디 내용입니다
*자료구조 내용은 sjm 멘토멘티에서 다룬적 있기 때문에, 정리하지 않았습니다
자바의 오류 & 예외처리
자바에서 발생하는 오류는 크게 컴파일 오류 와 런타임 오류 로 구분할 수 있다
컴파일 에러
소스 코드를 컴파일러가 바이트코드인
.class 파일로 변환하는 과정에서 문법적,구조적 문제가 발견될 때 발생하는 오류를 말한다
이 오류들은 프로그램이 실행되기 전에 발생하며, 수정하지 않으면 실행할 수 없다
주요 원인
문법 오류 (Syntax Error)
- 세미콜론(;) 누락
- 중괄호
{}나 괄호()짝이 맞지 않음 - 잘못된 예약어 사용
타입 불일치 (Type Mismatch)
- int 변수에 문자열 할당
- 메서드 반환형과 실제 반환 값 타입 불일치
정의되지 않은 식별자 사용
- 선언하지 않은 변수/메서드 사용
- 잘못된 클래스나 패키지 이름 참조
접근 제한자 및 패키지 문제
private멤버를 외부 클래스에서 접근하려고 함- import 문이 잘못되었거나 누락됨
런타임 에러
코드가 정상적으로 컴파일된 후, 실행 중에 발생하는 오류를 말한다.
즉, 문법적으로는 문제가 없어서 컴파일은 통과했지만, 프로그램 실행 도중 논리적,환경적 문제 때문에 예외(Exception)가 발생할 때 생긴다
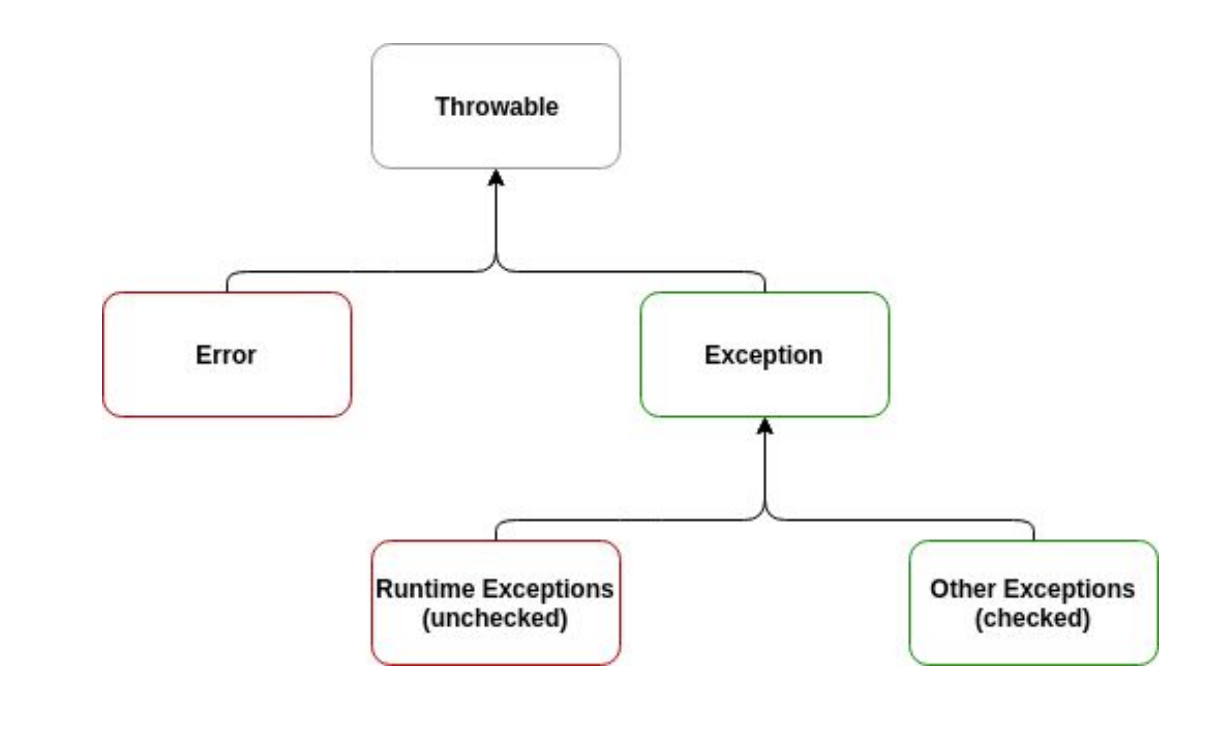
이미지 : Throwable 객체의 상속도
- 컴파일러가 발견하지 못함 -> 실행해야만 오류가 드러남
- 예외 (Exception) 또는 오류 (Error) 형태로 나타남
- 잘못된 입력,연산,리소스 접근 등이 주된 원인
주요 원인
잘못된 연산
- 0으로 나누기
public class Main {
public static void main(String[] args) {
int x = 10 / 0; // ArithmeticException 발생
}
}
배열 인덱스 범위 초과
public class Main {
public static void main(String[] args) {
int[] numbers = {1, 2, 3};
System.out.println(numbers[3]); // Index 3 out of bounds
}
}
NullPointerException (널 참조)
public class Main {
public static void main(String[] args) {
String text = null;
System.out.println(text.length()); // NullPointerException 발생
}
}
파일 또는 리소스 접근 오류
import java.io.FileReader;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("nonexistent.txt"); // FileNotFoundException
}
}
에러 & 예외
- 에러(Error) : JVM/시스템 레벨의 심각한 문제로, 코드에서 복구를 기대하기 어렵다
- 코드 수준에서 복구하기 어렵고, 설계나 로직 자체를 수정해야 한다
- 예외(Exception) : 프로그램 실행 도중 발생할 수 있는 문제
- 상황에 따라
try-catch또는throws로 처리할 수 있다
예외 처리
프로그램 실행 도중 발생할 수 있는 오류 (예외) 를 안전하게 감지하고 적절히 대응하여 프로그램이 갑자기 종료되지 않도록 하는 방법을 의미한다
- 프로그램의 안정성 확보
- 문제 원인을 파악하고 사용자에게 친절한 피드백 제공
- 예외 상황에 대한 대체 동작이나 정상 종료 유도
예외처리 방식
try-catch 블록
- 예외가 발생할 수 있는 코드를 try에 작성
- 발생한 예외를 catch에서 처리
public class Main {
public static void main(String[] args) {
try {
int x = 10 / 0; // ArithmeticException 발생
} catch (ArithmeticException e) {
System.out.println("0으로 나눌 수 없습니다: " + e.getMessage());
}
}
}
finally 블록
- 예외 발생 여부와 관계없이 항상 실행되는 코드 작성
- 주로 리소스 해제, 파일 닫기 등에 사용
public class Main {
public static void main(String[] args) {
try {
int[] arr = {1, 2};
System.out.println(arr[3]);
} catch (ArrayIndexOutOfBoundsException e) {
System.out.println("배열 범위를 벗어났습니다.");
} finally {
System.out.println("프로그램을 종료합니다."); // 항상 실행됨
}
}
}
throws 키워드
- 메서드 선언부에서 예외를 호출한 쪽으로 전파
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
readFile();
}
static void readFile() throws IOException {
FileReader fr = new FileReader("data.txt"); // 파일 없으면 예외 발생
}
}
throw 키워드
- 예외 객체를 직접 발생시킬 때 사용
public class Main {
public static void main(String[] args) {
try {
checkAge(15);
} catch (IllegalArgumentException e) {
System.out.println("예외 발생: " + e.getMessage());
}
}
static void checkAge(int age) {
if (age < 18) {
throw new IllegalArgumentException("18세 미만은 접근할 수 없습니다.");
}
}
}
예외처리 계층
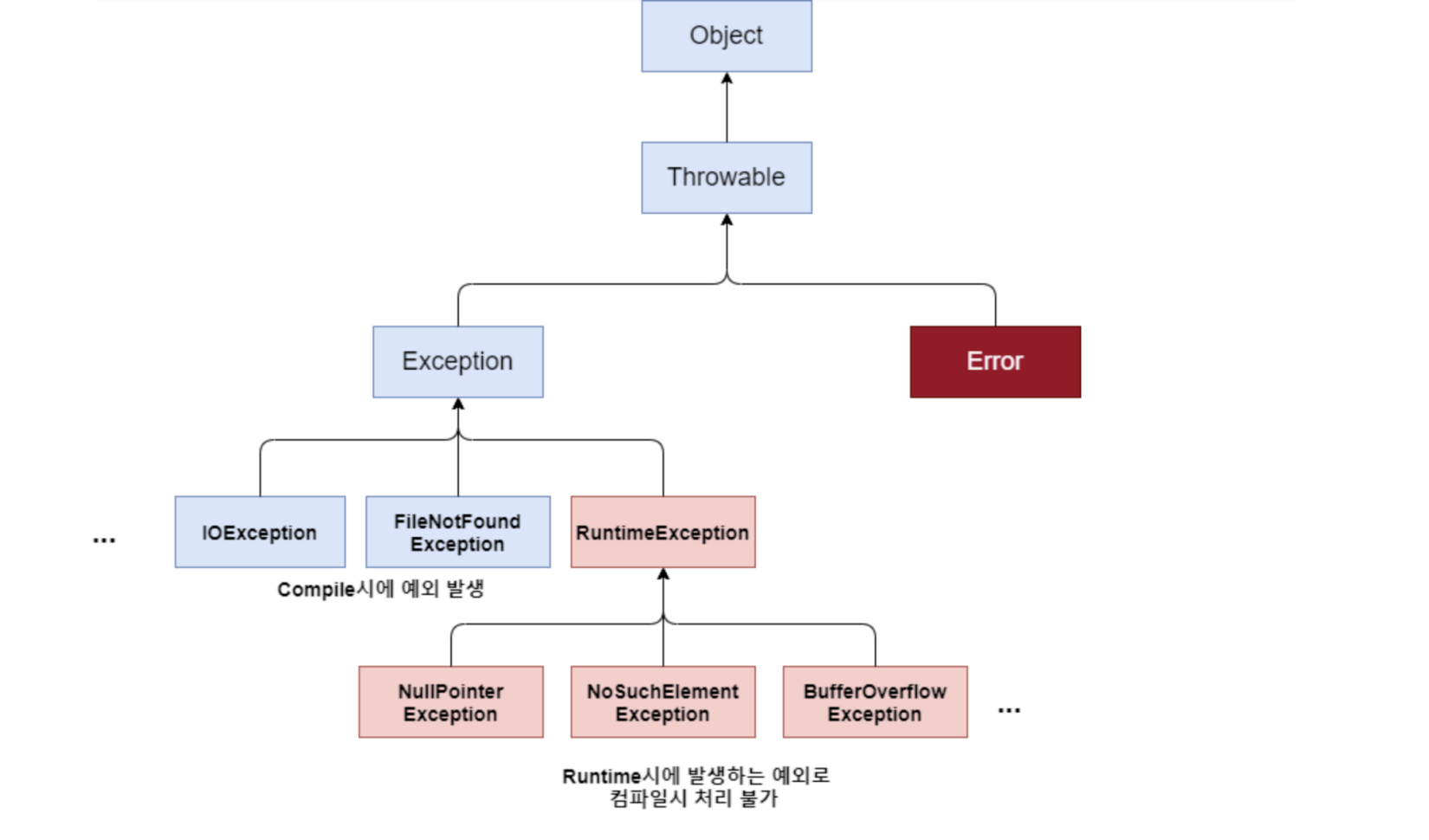
상단의 try-catch 문에서 Exception 타입 변수 e를 사용한 것을 본 것 처럼 자바에서 다루는 모든 예외는 Exception 클래스에서 처리한다
Exception 클래스는 다시 RuntimeException 과 그 외의 자식 클래스 그룹으로 나뉘게 된다
Exception 및 하위 클래스
- 사용자의 실수와 같은 외적인 요인에 의해 발생하는 예외
- 존재하지 않는 파일의 이름을 입력
(FileNotFoundException) - 입력한 데이터의 형식이 잘못됨
(DataFormatException)등
- 존재하지 않는 파일의 이름을 입력
RuntimeException 클래스 : 프로그래머의 실수로 발생하는 예외
- 배열의 범위를 벗어남 (IndexOutOfBoundException)
- null을 참조함 (NullPointerException) 등
Checked Exception / Unchecked Exception
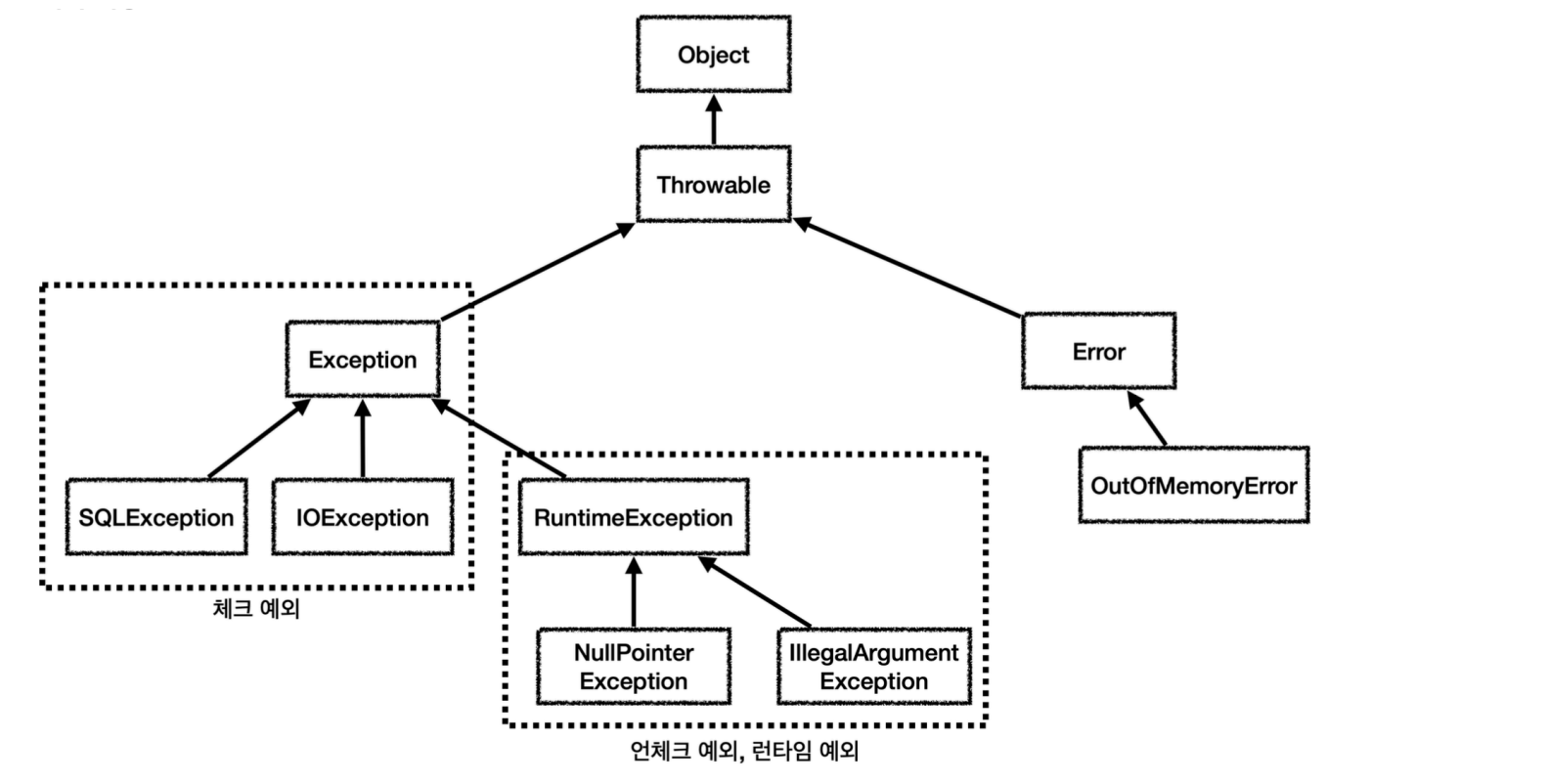
두 예외의 핵심적인 차이는 “반드시 예외 처리를 해야 하는가?” 이다
Checked Exception 은 컴파일 단계에서 체크하기 때문에 예외 처리를 하지 않는다면 컴파일이 되지 않는다
Checked Exception
- 처리여부 : 반드시 예외를 처리해야함
- 확인시점 : 컴파일 단계(실행 불가능)
- 예외 종류 : FileNotFoundException, DataFormatExvception 등
Unchecked Exception
- 명시적인 처리를 하지 않아도 됨
- 런타임 단계(실행은 가능)
- 예외 종류 : IndexOutOfBoundsException, NullPointerException 등
제네릭
Generic은 직역하면 ‘일반적인’ 이라는 뜻으로, 하나의 값이 여러 데이터 타입을 가질 수 있도록 하는 문법이다
클래스나 메서드를 타입 매개변수(Type Parameter) 를 사용해 정의함으로써, 다양한 타입을 안전하게 처리할 수 있도록 도와준다
컴파일 시점에 타입을 검사하므로, 타입 캐스팅 오류를 방지하고 코드 재사용성을 높이는 것이 핵심 목적이다
- 타입 안정성 :컴파일 시점에 타입을 검사해, 잘못된 타입 사용으로 인한 런타임 오류를 줄임
- 형변환 제거: Object를 사용할 때처럼 매번 캐스팅할 필요가 없음
- 재사용성: 같은 로직을 여러 타입에 대해 중복 작성하지 않아도 됨
제네릭 구조

- 클래스명 우측의
< >안에 들어가는 알파벳은 메소드가 매개변수를 사용하는 것과 비슷해 타입 매개변수 라고 부른다 - 클래스를 만들 때, 클래스명 우측의
< >안에 타입 매개변수 기호를 지정함으로써 제네릭을 선언할 수 있다. // <T> : 타입 매개변수 선언 public class Box<T> { private T value; // T 타입의 필드 public void setValue(T value) { // T 타입의 매개변수 this.value = value; } public T getValue() { // T 타입의 반환값 return value; } }- 타입 매개변수를 선언 (T, E, K, V 등이 관례적)
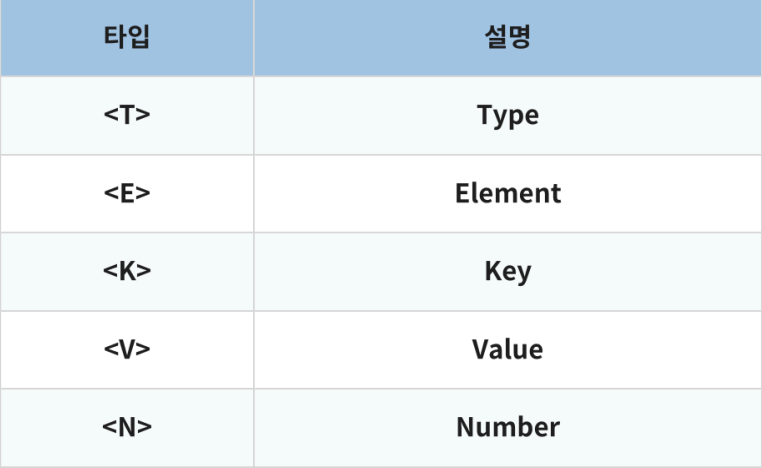
- Box: 타입 매개변수를 실제 타입(String)으로 지정
제네릭의 구성 요소
제네릭 클래스
public class Box<T> {
private T item;
public void set(T item) { this.item = item; }
public T get() { return item; }
}
Box<String> strBox = new Box<>();
strBox.set("Hello");
String value = strBox.get();제네릭 클래스 선언
- 이 클래스 내부에서 T는 아직 결정되지 않은 타입을 의미한다
private T item;: T 타입의 필드를 선언. Box가 다룰 값의 타입은 객체 생성 시 결정된다- set / get 메서드 : T 타입으로 값을 넣고 꺼낼 수 있다
Box<String>: 타입 매개변수 T를 String으로 지정 -> 이제 Box는 String 전용 박스가 됨
사용 예제
new Box<>(): 다이아몬드 연산자<>를 사용해 타입 추론 -> 컴파일러가 String을 자동으로 추론한다strBox.set("Hello"): String 타입만 허용 -> 잘못된 타입을 넣으면 컴파일 오류String value = strBox.get(): 꺼낼 때 별도의 형변환이 필요 없음- 제네릭이 없었다면
(String) strBox.get()같은 캐스팅이 필요했을 것
Box<T> 는 선언 시 타입을 고정하지 않아서, 나중에 Box<Integer> 나 Box<Double> 처럼 재사용할 수 있으며, 컴파일 시 타입 검증 덕분에 안전하게 값을 다룰 수 있다
제네릭 인터페이스
public interface Repository<T> {
void save(T entity);
T findById(int id);
}
public class UserRepository implements Repository<User> {
@Override
public void save(User entity) { /* 저장 로직 */ }
@Override
public User findById(int id) { return new User(); }
}제네릭 인터페이스 선언
save(T entity): 타입 T의 객체를 저장한다findById(int id): 타입 T의 객체를 찾아 반환한다- Repository는 구체적인 타입에 의존하지 않으므로, 재사용성과 유연성이 높다
- ex)
Repository<User>, Repository<Product>, Repository<Order>등으로 모두 활용 가능
인터페이스 구현
implements Repository<User>: T를 User 로 구체화save(User entity)와findById()는 User 타입 전용이 된다@Override: 인터페이스에서 선언한 메서드를 실제로 구현
Repository<T> 를 기반으로 여러 엔티티의 저장소를 쉽게 만들 수 있다
public class ProductRepository implements Repository<Product> { ... }
public class OrderRepository implements Repository<Order> { ... }제네릭 메서드
public class Utils {
public static <T> void print(T item) {
System.out.println(item);
}
}
Utils.print(123); // T -> Integer
Utils.print("Hello"); // T -> String- 반환 타입 void 앞에 위치하여 이 메서드에서 T라는 타입을 사용하겠다는 의미
- 클래스 전체가 제네릭일 필요는 없음
- 메서드 단위에서만 제네릭을 사용할 수 있음
T item: 매개변수의 타입으로 T를 사용 → 호출할 때 타입이 결정됨
다중타입 제네릭
class Pair<K, V> {
private K key;
private V value;
public Pair(K key, V value) {
this.key = key;
this.value = value;
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
}
Pair<String, Integer> pair = new Pair<>("나이", 25);클래스 선언부
- <K, V>
- K: Key의 약자, 첫 번째 타입 매개변수
- V: Value의 약자, 두 번째 타입 매개변수
다중 타입 매개변수를 사용하면 서로 다른 두 타입을 한 클래스에서 동시에 다룰 수 있다
- 필드
private K key;-> 첫 번째 타입private V value;-> 두 번째 타입
- 생성자
- 전달받은 타입 K, V를 그대로 필드에 저장
- Getter 메서드
getKey()는 K 타입 반환getValue()는 V 타입 반환
제한된 타입 매개변수 (Bounded Type Parameters)
상한 제한 (Upper Bound)
class Calculator<T extends Number> {
public double square(T num) {
return num.doubleValue() * num.doubleValue();
}
}- extends Number는 Upper Bound를 의미
- T는 Number 클래스이거나 그 하위 클래스(Integer, Double, Float 등) 만 허용
- String, Boolean 같은 타입은 사용할 수 없음-> 타입 안정성 확보
하한 제한 (Lower Bound, 와일드카드에서 사용)
public static void addNumbers(List<? super Integer> list) {
list.add(10); // Integer 또는 상위 타입 허용
}<? super Integer>: 하한 제한(lower bounded wildcard)ex) :List<Integer>, List<Number>, List<Object>모두 허용- 이렇게 하면 Integer 값을 안전하게 추가(add) 할 수 있음
- 의미 : Integer 또는 그 상위 타입(Object, Number 등) 의 리스트를 받을 수 있음
와일드카드(Wildcards)
<?>: 알 수 없는 임의의 타입<? extends T> : T또는 그 하위 타입<? super T>: T 또는 그 상위 타입
public static void printList(List<?> list) {
for (Object o : list) {
System.out.println(o);
}
}
List<Integer> nums = List.of(1, 2, 3);
List<String> strs = List.of("A", "B");
printList(nums);
printList(strs);메서드 오버라이드 & 익명 클래스
메서드 오버라이드
- 상속 관계에서, 부모 클래스의 메서드를 자식 클래스가 재정의 하는 것
- 같은 메서드 이름, 매개변수, 반환 타입을 가져야 함
- 런타임에 자식 클래스의 메서드가 우선 호출됨 -> 다형성의 핵심
class Animal {
void sound() {
System.out.println("동물이 소리를 냄");
}
}
class Dog extends Animal {
@Override
void sound() {
System.out.println("삐약삐약");
}
}
public class Main {
public static void main(String[] args) {
Animal a = new Dog(); // 다형성
a.sound(); // 출력: 삐약삐약
}
}익명 클래스
- 이름이 없는 클래스
- 클래스 선언과 동시에 객체를 생성하는 방식
- 일회성 사용 목적으로, 주로 인터페이스나 추상 클래스 구현, 또는 상속 후 메서드 오버라이드 할 때 사용
new 부모클래스(또는 인터페이스)() {
// 메서드 재정의
};특징
- 클래스 선언 + 객체 생성이 동시에 이루어진다
- 이름이 없으므로 재사용 불가
- 코드 간결, 하지만 너무 많이 쓰면 가독성이 떨어질 수 있음
- 주로 이벤트 핸들러, 콜백, 간단한 구현체에 사용
인터페이스 구현
interface Greeting {
void sayHello();
}
public class Main {
public static void main(String[] args) {
Greeting g = new Greeting() { // 익명 클래스
@Override
public void sayHello() {
System.out.println("안녕하세요!");
}
};
g.sayHello();
}
}Greeting 인터페이스를 별도의 클래스 파일로 구현하지 않고 즉석에서 정의 후 객체 생성
추상 클래스 상속
abstract class Animal {
abstract void sound();
}
public class Main {
public static void main(String[] args) {
Animal cat = new Animal() { // 익명 클래스
@Override
void sound() {
System.out.println("야옹~");
}
};
cat.sound();
}
}Animal 추상 클래스를 상속받아, 필요한 메서드만 구현하고 바로 객체 생성
클래스 상속
class Person {
void introduce() {
System.out.println("저는 사람입니다.");
}
}
public class Main {
public static void main(String[] args) {
Person p = new Person() { // 익명 클래스
@Override
void introduce() {
System.out.println("저는 학생입니다.");
}
};
p.introduce(); // "저는 학생입니다."
}
}람다 표현식
람다 표현식은 익명 함수(anonymous function) 를 간단히 표현하는 문법으로, 자바 8 버전 부터 도입되었음
즉, 메서드를 하나의 식(expression)으로 간단히 표현할 수 있는 방법 -> (매개변수목록) -> { 실행문 }
- 함수형 인터페이스 (SAM: 단 하나의 추상 메서드만 가지는 인터페이스) 타입 위치
- 보일러플레이트 제거, 컬렉션/스트림 처리 간결화, 비동기 이벤트 코드 가독성 증가
// 기존 익명 클래스 방식
Runnable run1 = new Runnable() {
@Override
public void run() {
System.out.println("Hello");
}
};
// 람다 표현식
Runnable run2 = () -> {
System.out.println("Hello");
};문법 단축 규칙
-
- 매개변수가 하나일 경우 괄호 생략 가능
(x) -> x * x x -> x * x -
- 실행문이 한 줄일 경우 중괄호 {} 생략 가능
(a, b) -> { return a + b; } (a, b) -> a + b -
- 리턴문만 존재하면 return 키워드 생략 가능
(x, y) -> return x + y; (x, y) -> x + y; - 특징
- 익명성 : 이름 없는 함수, 재사용보다는 일회성 작업에 적합
- 간결성: 불필요한 코드 줄임
- 함수형 인터페이스와 함께 사용됨
함수형 인터페이스
추상 메서드를 딱 하나만 가지는 인터페이스
- 자바 8부터 람다 표현식과 함께 본격적으로 사용됨
- 람다 표현식 -> 함수형 인터페이스의 구현체 객체를 반환하는 원리로 동작
특징
추상 메서드 1개만 존재해야 함
- 여러 개 있으면 함수형 인터페이스가 아님
- 단, default 메서드나 static 메서드는 여러 개 있어도 됨
@FunctionalInterface 어노테이션 사용 권장
- 강제는 아니지만, 붙이면 컴파일러가 규칙 위반을 체크해줌
- 주로 람다, 메서드 참조
::와 결합해서 사용됨
예시
@FunctionalInterface
interface MyFunction {
int add(int a, int b);
}
public class Test {
public static void main(String[] args) {
MyFunction f = (x, y) -> x + y;
System.out.println(f.add(3, 5)); // 8
}
}자바에서 제공하는 주요 함수형 인터페이스 (java.util.function)
Predicate : 매개변수 T -> boolean 반환
Predicate<Integer> isEven = n -> n % 2 == 0;
System.out.println(isEven.test(4)); // trueFunction<T,R> : T -> R 변환
Function<String, Integer> length = s -> s.length();
System.out.println(length.apply("hello")); // 5Consumer : T 받아서 사용 (반환값 없음)
Consumer<String> printer = s -> System.out.println(s);
printer.accept("Hi!"); // Hi!Supplier : 매개변수 없고 T 리턴
Supplier<Double> random = () -> Math.random();
System.out.println(random.get()); 자바 공식 문서에 나머지 더 있음
메서드 참조
기존에 이미 정의된 메서드를 그대로 참조하여 람다 표현식을 더 간결하게 작성하는 방법
정의
함수형 인터페이스에 맞춰 기존 메서드/생성자를 참조 형태로 넘기는 문법
- 동치: 항상 어떤 람다식과 동치, 기능/성능상 거의 차이 없고, 가독성이 좋아진다
형태 4가지
- 정적 메서드: Type::staticMethod
- 특정 객체의 인스턴스 메서드 (바운드):
instance::method - 임의 객체의 인스턴스 메서드 (언바운드):
Type::instanceMethod - 생성자/배열 생성자:
Type::new,Type[]::new
람다와의 관계
list.forEach(s -> System.out.println(s));
list.forEach(System.out::println);차이점은 표기 뿐, 자바 컴파일러는 둘 다 함수형 인터페이스 시그니처에 맞춰 연결한다
내부적으로는 보통 invokedynamic 을 통한 람다 팩토리 (메서드 핸들) 로 구현되며, 성능 차이를 기대하진 않는다
문법과 파라미터 매칭 규칙
함수형 인터페이스의 추상 메서드 시그니처 (SAM) 와 참조 대상 메서드의 시그니처가 호환되어야 한다
간단 매핑 규칙
- 정적 메서드
Type::staticMethod: 람다(a,b,c) -> Type.staticMethod(a,b,c) - 바운드 인스턴스
obj::method: 람다(a,b) -> obj.method(a,b) - 언바운드 인스턴스
Type::method-> 람다(receiver, a, b) -> receiver.method(a,b)(첫 번째 인자가 수신 객체로 들어감) - 생성자
Type::new: 람다(a,b) -> new Type(a,b) - 배열 생성자
Type[]::new: 람다(n) -> new Type[n]
4가지 형태 & 예제
정적 메서드 참조 — Type::staticMethod
Function<String, Integer> parse = Integer::parseInt; // s -> Integer.parseInt(s)
BiPredicate<List<String>, String> contains = Collections::binarySearch;
// 시그니처 주의 -> 보통은 List::contains 가 자연스러움특정 객체의 인스턴스 메서드(바운드) — obj::method
var out = System.out;
Consumer<String> printer = out::println; // s -> out.println(s)
Stream.of("a","b","c").forEach(out::println);임의 객체의 인스턴스 메서드(언바운드) — Type::method
Function<String, Integer> length = String::length; // s -> s.length()
BiFunction<String, String, Boolean> startsWith = String::startsWith;
// (s, prefix) -> s.startsWith(prefix)
Comparator<String> cmp = String::compareToIgnoreCase; // (a,b) -> a.compareToIgnoreCase(b)생성자 & 배열 생성자 — Type::new, Type[]::new
Supplier<List<String>> listMaker = ArrayList::new; // () -> new ArrayList<>()
Function<Integer, int[]> intArray = int[]::new; // n -> new int[n]
Function<String, File> toFile = File::new; // path -> new File(path)
BiFunction<Integer, Integer, Point> pointMaker = Point::new; // (x,y) -> new Point(x,y)Stream
List<Person> people = ...
List<String> names = people.stream()
.map(Person::getName) // p -> p.getName()
.filter(name -> !name.isBlank())
.toList();
Map<Integer, List<Person>> byAge = people.stream()
.collect(Collectors.groupingBy(Person::getAge));
int totalNameLen = people.stream()
.map(Person::getName)
.mapToInt(String::length)
.sum();Optional
String name = optionalPerson
.map(Person::getName)
.orElseGet(this::fallbackName); // () -> this.fallbackName()Comparator
people.sort(
Comparator.comparing(Person::getAge)
.thenComparing(Person::getName, String::compareToIgnoreCase)
);메서드 체이닝과 조합
Function<Person, Integer> age = Person::getAge;
Function<Person, String> name = Person::getName;
people.stream()
.sorted(Comparator.comparing(age).thenComparing(name))
.forEach(System.out::println);오버로딩, 제네릭, 예외
오버로딩 모호성
- 메서드 이름만 쓰면 여러 오버로드 중 어떤 걸 고를지 모호할 수 있음
// 예: Files.newBufferedWriter(Path) vs Files.newBufferedWriter(Path, Charset, OpenOption...)
Supplier<Writer> s = ??? // Files::newBufferedWriter 는 모호
// 해결 1) 람다로 풀기
Supplier<Writer> s1 = () -> Files.newBufferedWriter(path);
// 해결 2) 타깃 타입을 더 구체적으로
Function<Path, BufferedWriter> f = Files::newBufferedWriter;
// 그래도 모호하면 캐스팅으로 시그니처를 고정제네릭 메서드 참조
제네릭 타입 추론이 애매할 때는 타입 파라미터 명시 또는 타입 캐스팅으로 힌트를 준다
<T> T identity(T t) { return t; }
// Function<String, String> id = this::identity; // OK (보통 추론됨)
// 추론 실패 시: Function<String, String> id = (Function<String, String>) this::identity;체크 예외(checked exception)
참조 대상 메서드가 체크 예외를 던지면, 타깃 함수형 인터페이스도 그 예외를 선언해야 한다
Function<Path, String> readAll = Files::readString; // IOException 던짐
// Function은 throws 선언이 없으므로 컴파일 에러
// 솔루션 1) 람다 + try/catch 로 감싸기
Function<Path, String> safeRead = p -> {
try { return Files.readString(p); }
catch (IOException e) { throw new UncheckedIOException(e); }
};
// 솔루션 2) throws 있는 커스텀 함수형 인터페이스 정의
@FunctionalInterface interface IOFunction<T,R> { R apply(T t) throws IOException; }
IOFunction<Path, String> ioRead = Files::readString; // OK스트림
사전의 stream의 뜻은 '흐르다'라는 의미이지만 개발에서의 stream은 '데이터의 흐름'을 의미한다
Java 8부터 추가된 스트림은 “데이터를 선언적으로 처리”하기 위한 기능이다
배열이나 컬렉션 같은 데이터 소스를 스트림으로 변환해 필터링, 매핑, 집계 등을 간결하게 수행할 수 있다
개념
- 데이터 소스 (배열, 컬렉션, ... 등) : 스트림 생성
- 중간 연산 (filter, map, sorted …) : 변환/가공
- 최종 연산 (forEach, collect, count, reduce …) : 결과 산출
특징
- 내부 반복 (코드를 직접 돌리는 게 아니라 스트림이 알아서 처리)
- 지연 연산 (최종 연산이 실행될 때만 실제 계산 시작)
- 병렬 처리 지원
(parallelStream)
스트림 생성
// 리스트
Stream<String> s1 = List.of("a", "b", "c").stream();
// 배열
Stream<Integer> s2 = Arrays.stream(new Integer[]{1,2,3});
// 정적 팩토리
Stream<Double> s3 = Stream.of(1.0, 2.0, 3.0);
// 무한 스트림
Stream<Integer> even = Stream.iterate(0, n -> n + 2); // 0,2,4,...
Stream<Double> randoms = Stream.generate(Math::random); // 랜덤값 무한중간 연산
List<String> names = List.of("kim", "lee", "park", "kim");
names.stream()
.filter(n -> n.length() >= 3)
.map(String::toUpperCase)
.distinct()
.sorted()
.forEach(System.out::println);
// 결과: KIM, LEE, PARK중간 연산은 스트림을 변환하지만 즉시 실행되지 않고, 최종 연산이 있어야 실행된다
- filter: 조건으로 걸러내기
- map / flatMap: 요소를 변환
- distinct: 중복 제거
- sorted: 정렬
- limit / skip: 일부만 가져오기
최종 연산
List<Integer> nums = List.of(1,2,3,4,5);
// 합계 reduce
int sum = nums.stream()
.reduce(0, (a,b) -> a+b); // 0부터 시작해서 누적
// 결과: 15
// Collectors 활용
List<Integer> even = nums.stream()
.filter(n -> n % 2 == 0)
.collect(Collectors.toList());
// 결과: [2,4]최종 연산을 만나면 스트림 파이프라인이 실행된다
- forEach: 요소별 작업 실행
- collect: 리스트, 맵, 세트 등으로 수집
- reduce: 누적해서 하나의 결과 도출
- count, max, min, anyMatch, allMatch, findFirst, findAny 등
스트림과 컬렉션의 차이
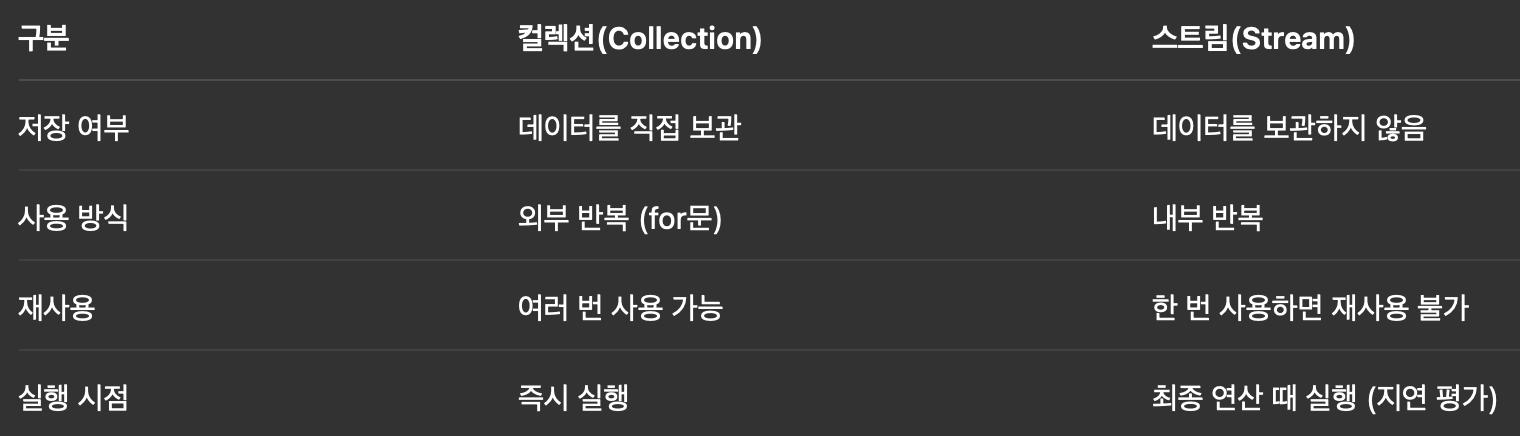
Optional
자바 Optional 은 값이 있을 수도 있고 없을 수도 있는 상황을 더 안전하고 명확하게 표현하기 위해 도입된 컨테이너 클래스이다
자바에서 가장 흔한 에러는 바로 NullPointerException(NPE) 이다
전통적으로 null을 써서 “값 없음”을 표현했지만,
• null 은 실수하기 쉽고, 코드 의도도 불명확합니다.그래서 Optional 은 null을 직접 다루지 않고도 안전하게 값의 부재를 표현할 수 있는 도구의 역할을 한다
Optional 만들기
Optional<String> emptyOpt = Optional.empty(); // 비어있는 Optional
Optional<String> nameOpt = Optional.of("Alice"); // 값 있는 Optional (null 불가)
Optional<String> maybeOpt = Optional.ofNullable(null); // null 가능값 꺼내기
안전하게 꺼내기
String name = nameOpt.get(); // 값이 없으면 NoSuchElementException 발생 (비추천)위 코드 대신 안전한 메서드를 쓰는 게 원칙이다
String n1 = maybeOpt.orElse("기본값"); // 값 없으면 기본값 반환
String n2 = maybeOpt.orElseGet(() -> "생성"); // 값 없으면 함수 실행
String n3 = maybeOpt.orElseThrow(); // 값 없으면 예외 던짐값이 있는지 확인
if (maybeOpt.isPresent()) {
System.out.println(maybeOpt.get());
}
maybeOpt.ifPresent(v -> System.out.println("값 있음: " + v));
maybeOpt.ifPresentOrElse(
v -> System.out.println("값 있음: " + v),
() -> System.out.println("값 없음")
);체이닝 (map, flatMap, filter)
Optional 은 스트림과 비슷하게 함수형 스타일을 지원한다
Optional<String> nameOpt = Optional.of("Alice");
int len = nameOpt
.map(String::length) // 값이 있으면 변환
.orElse(0); // 없으면 0
Optional<String> maybe = Optional.of("Alice");
maybe.filter(s -> s.startsWith("A"))
.ifPresent(System.out::println); // Alice
Optional<Student> studentOpt = findStudent();
String city = studentOpt
.flatMap(Student::getAddress) // Optional<Address>
.map(Address::getCity) // Optional<String>
.orElse("Unknown"); // 없으면 기본값주의
Optional은 필드로 쓰지 말 것
class User {
Optional<String> name; // 좋지 않은 코드
}Optional 은 리턴 타입에 쓰는 게 맞다 (값의 부재를 표현할 때)
컬렉션 안에 Optional을 중첩하지 말 것
List<Optional<T>> 같은 형태는 불필요하게 복잡해지니, 대신 빈 컬렉션이나 필터링으로 처리하는 게 낫다
무조건 Optional 쓰라는 건 아님
“값이 없을 수 있음”이 코드 의미상 중요한 경우에만 사용한다
단순히 null 체크만 하고 끝나는 상황이면 오히려 코드가 장황해질 수 있기 때문이다
'Java' 카테고리의 다른 글
| null 안전하게 처리하기 (0) | 2025.11.03 |
|---|